How we built our all-in-one Search
“Was it on Slack or Email? Or maybe it was Google Drive?”
“...or maybe they didn’t actually share it with me?”
In the new world of work, with remote teams collaborating online, this scenario will be all too familiar to many. Not only does it stop you from getting work done, it also makes it much harder for people to get context on what’s going on across their organization.
Qatalog’s recently upgraded Workplace Search feature is designed to help solve this problem, making it quick and simple to find the files and documents that you want, no matter where they’re stored. Unified search has become particularly important for remote and distributed companies, helping to avoid constant interruptions to ask where files are, something which is critical for teams working across time zones who can’t afford to wait until their colleagues start work six hours later.
The end result is that cross-functional work becomes more visible and accessible, while also ensuring that everyone can actually focus on getting their work done.
Qatalog makes all this possible by integrating with a host of applications, such as Google Drive, Asana, Microsoft Office, Gmail, Outlook, and connecting relevant work, in Qatalog, across teams. Despite all these integrations, which create thousands more potential matches, your search will still return relevant results every time, and at lightning speed.
So, how on earth does it work? I spoke to the Engineering team, to find out.
How do you make sure people get relevant search results, even with all of these integrations?
Large organizations often suffer from this problem, because they are working across lots of tools, creating tens of thousands of documents, and the keyword density for certain terms quickly becomes too high to yield useful results.
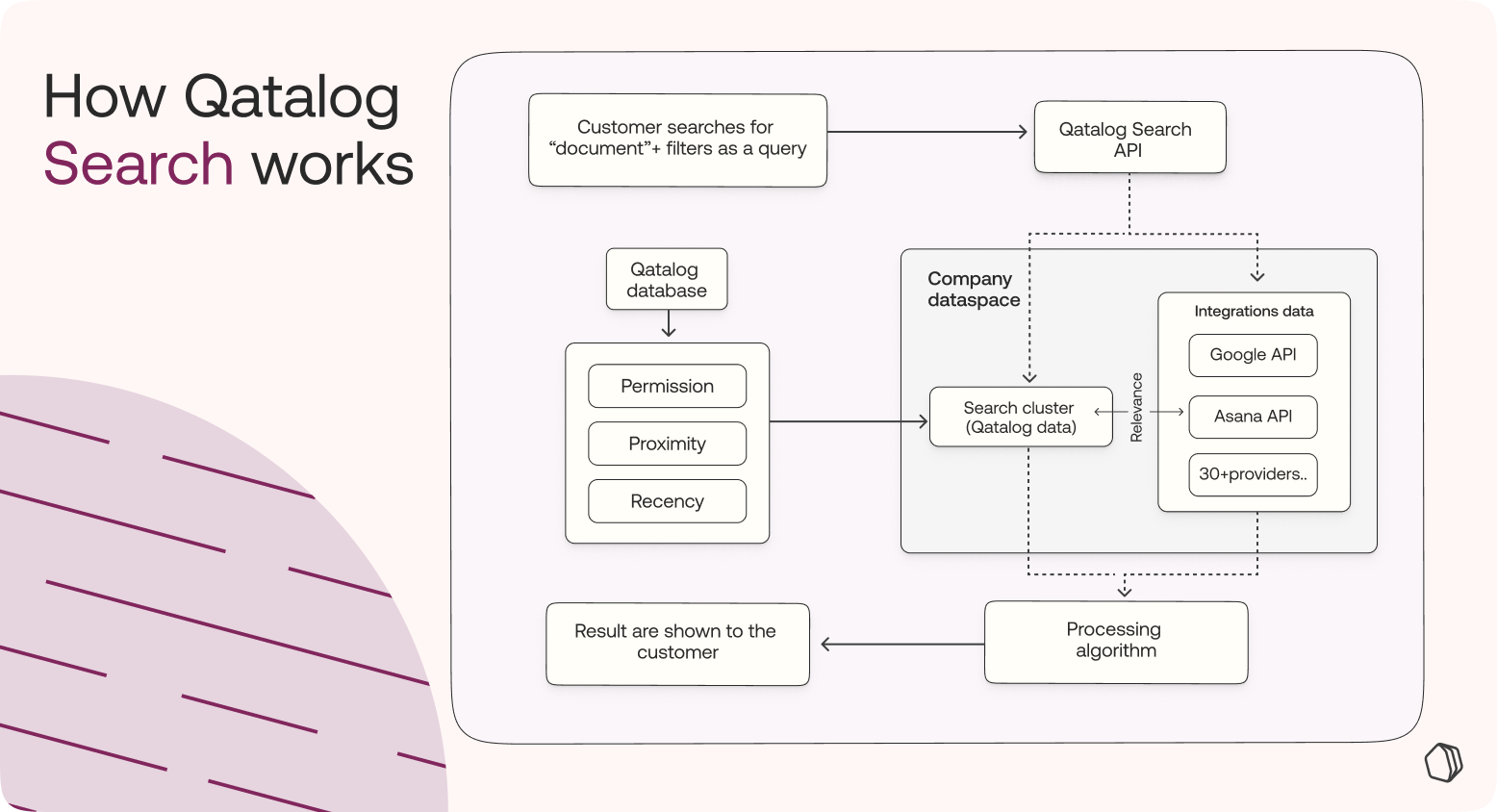
Our fundamental advantage is that we understand the structure of an organization and how each person relates to their work because that’s inherent to the way Qatalog works. For example, Qatalog knows what team someone is in, what Projects they are working on, and who they are collaborating with regularly. All of this data forms our ‘Workgraph’, which allows us to make sure the results are as relevant as they can be.
Why doesn’t all of this information slow it down? How is it still so fast?
The speed of search can become a potential problem when you have so much information. The short answer is that we use a cluster of virtual machines and services dedicated to search only, which improve speed and scalability. The search cluster reads data from Qatalog, which is in tabular form and indexes it in ‘document’ form. This makes it much easier to calculate relevancy. It also means when there's a high load in the system, we instantly increase the number of servers, which ensures it’s always super fast. And when this is combined with data from any API integration, it goes through our processing algorithm where we calculate the relevancy and reorder it again, before the results are shown to the customer. This all happens in about one second!
And why is this different from other search tool providers in the market?
Most search-only providers don’t have the context that we have from Qatalog users’ Workgraph, meaning it’s significantly harder for them to know what’s relevant. Often they will build on top of API search integrations for all the different tools and spit out results using the limited information they have. This typically results in a much slower search experience, with very little guarantee of getting useful results.
What else have you done to make it easier to find things quickly?
We’ve added simple features like filtering to allow customers to drill down and get more granular results. For example, you can filter by person, by integration, or by date. So if you know a particular person shared a document with you, but you don’t know where or when you can narrow it down much faster. In addition, you can also search by the ‘type of work’. So, if you know something was shared in a Post on Qatalog, you can filter by ‘Posts’ and ‘Person’.
Are there systems in place to ensure security and privacy?
All of Qatalog has been designed with security and privacy in mind. The crucial thing to mention with Search is that we don’t index data from the integrations, so we don’t have customer data from all those different tools sitting on our server. This means you also don’t have to worry about permissions and ownership either, because we just use permissions from the API tokens. Instead, we enhance the results from the API with our own relevancy score. All of this lowers the security risk and means no maintenance of permissions and data syncs.